Oblique Thinking Hour – Group Concept Mapping
We ran our most recent Oblique Thinking Hour sessions, two of them one-week apart, on the topic of Group Concept Mapping.
In the first week, we took a simple sentence stem prompt:
"When I think of digital infrastructure that empowers and enables, I think of __________."
and asked participants to connect in small group break-out rooms to discuss and submit responses to that prompt. We received about 58 responses from participants that illustrated diverse interpretations of digital infrastructure.
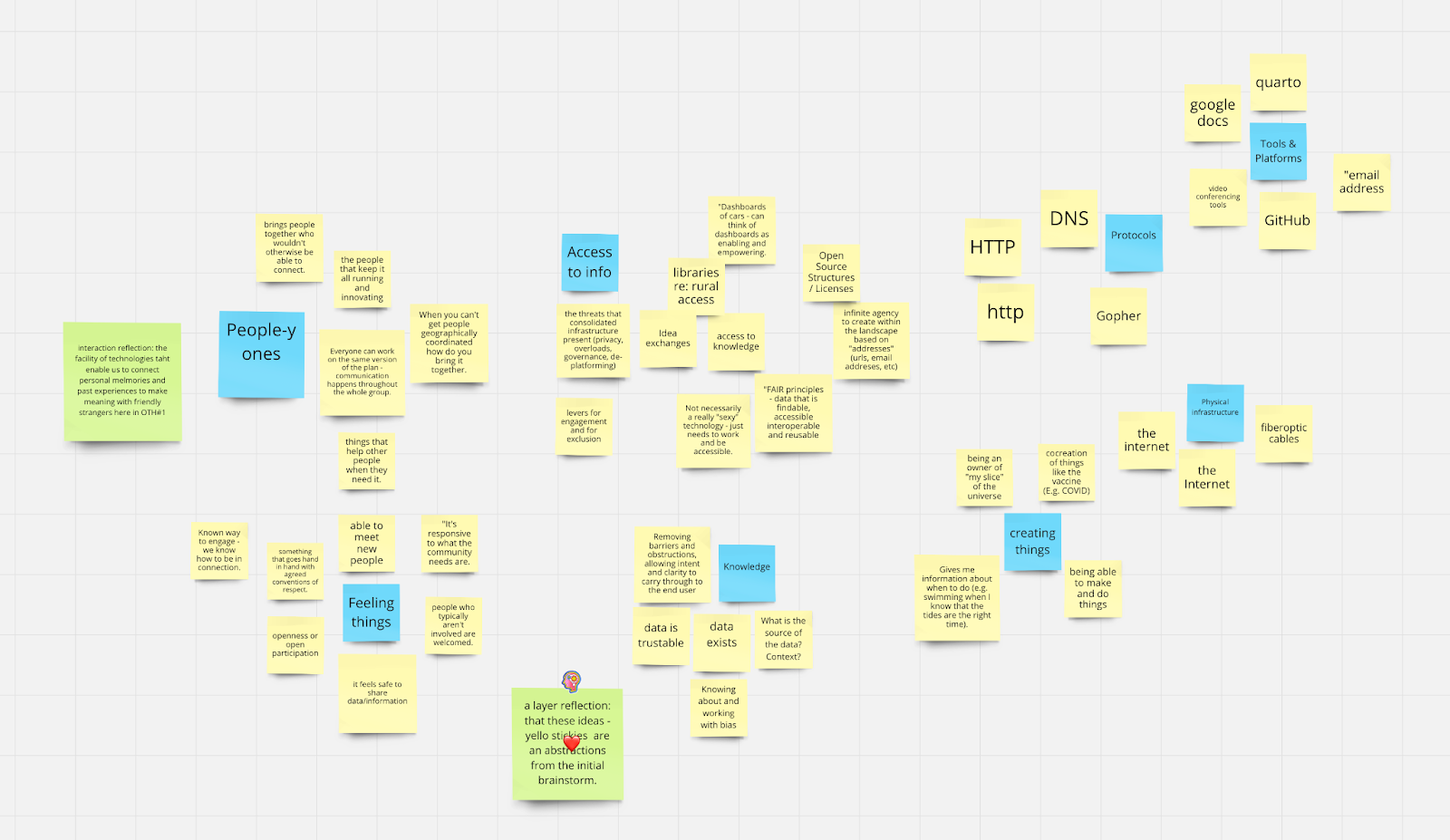
We then placed all of those responses in a Miro board and worked to manually cluster / categorize the responses as a group. It was a lot of fun - our cursors were moving all over the board as we spoke aloud about our grouping decisions in real-time. Once we settled on the clusters, we then discussed how to name them (the blue sticky notes in the image above).
Between the two weeks, we asked for contributions from a broad community using social media and direct contacts. We used the same prompting question, with limited guidance, and a general explanation of the background of the work and project. This didn’t quite go as planned. We had a lot of boosting of the effort, but very few additional responses. While trying to keep responses general and un-guided, we think we may have had a prompt that didn’t welcome contributions without some additional context.
We kept going and in our second oblique thinking hour, we tried out an automated approach to clustering.
Our approach to the automated clustering went as follows*:
- Take a vector (list) of text (responses, one per line).
- Present each line to an “embedding” algorithm. This takes the text and places it in a multi-dimensional space. Related text (conceptually) tends to cluster with other text in this “hyper-space.”
- Collapse the hyperspace to a smaller dimensional space (Principal Component Analysis)
- Cluster (simple method with k-means here today).
- Feed the contents of the cluster (each item) to an LLM with the following prompt:
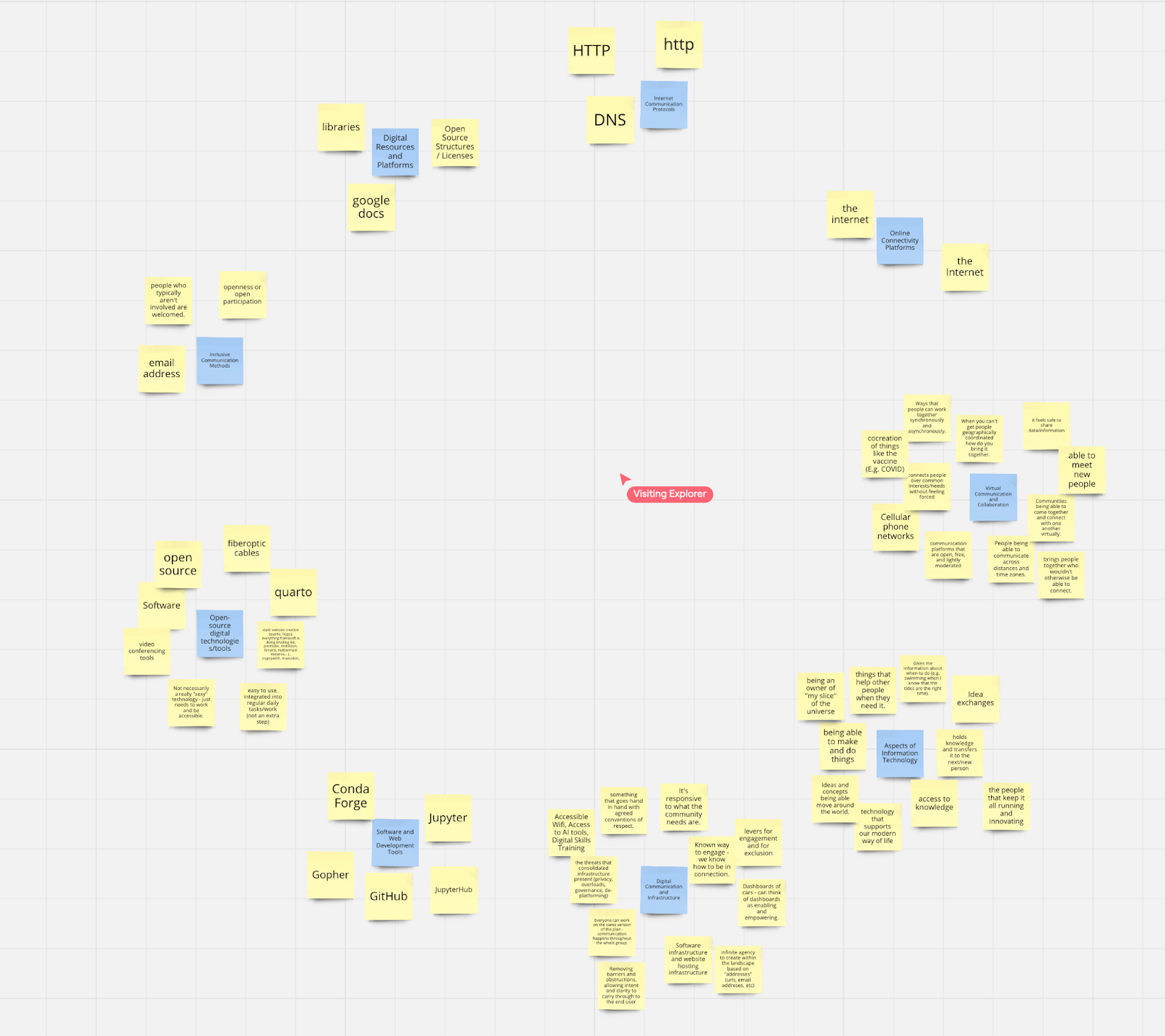
We had a really interesting discussion after the conversation, comparing the results of our human clustering to the automated approach. We noticed, for example, that the number of categories we asked the algorithm to produce (i.e., the number of blue stickies) influenced how many “outliers” we ended up with and how much redundancy there was across the groupings.
We also discussed how the choices Jonah made in building the automated tooling might have influenced the result, blurring the line between what is “automated” and what is “manual.” There are lots of examples of this kind of scenario out in the world: What datasets are being used to train a language model, and how does that influence its performance? How do decisions about integrating an automated tool in a workflow that has other tools adjacent in the workflow (i.e., interoperability) affect outcomes, including the amount of work humans have to do to fill the gaps in the workflow?
All in all, we’re excited to keep playing with this approach and finding ways that it can be useful. We think that in situations where you have a lot of people, or a lot of data, automated tools such as these can be useful for generating “first-cut” analyses. And perhaps what we’re most excited about is how the process of doing group concept mapping–whether manually or automated–prompts such interesting discussions about the concepts being mapped.
How might you use Group Concept Mapping in your organization or team? Do you already do something similar? Let us know!
*Source code available as a Gist.
Member discussion